
背景
最近发现其中一套生产环境的MySQL集群主从数据同步延迟问题严重,从库积累了很多中继日志,导致分配数据库磁盘使用率超过90%告警。这问题从排查到处理过程耗费了很长时间,在这里记录下整个处理过程,希望能给其他遇到此类问题的朋友一点帮助。
先介绍下环境情况,这套MySQL集群使用的k8s容器化部署,使用的三节点MySQL MGR复制模式,数据存储使用的ceph rbd块存储
– MySQL版本:8.0.19
– Ceph版本:12.2.10(Luminous)
排查
最早发现主从数据库之间很多表数据不同步,MGR集群状态正常
检查操作系统负载情况
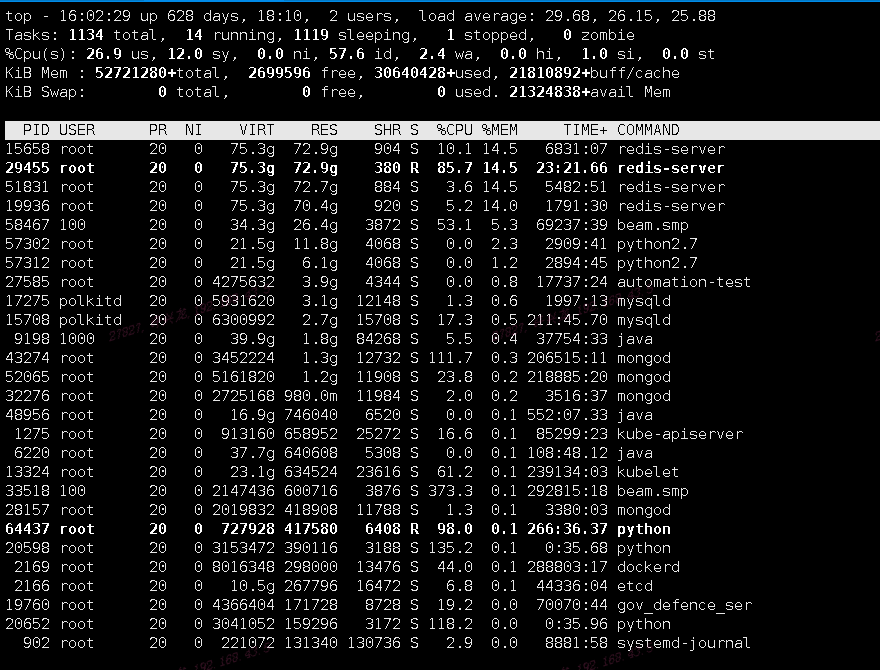
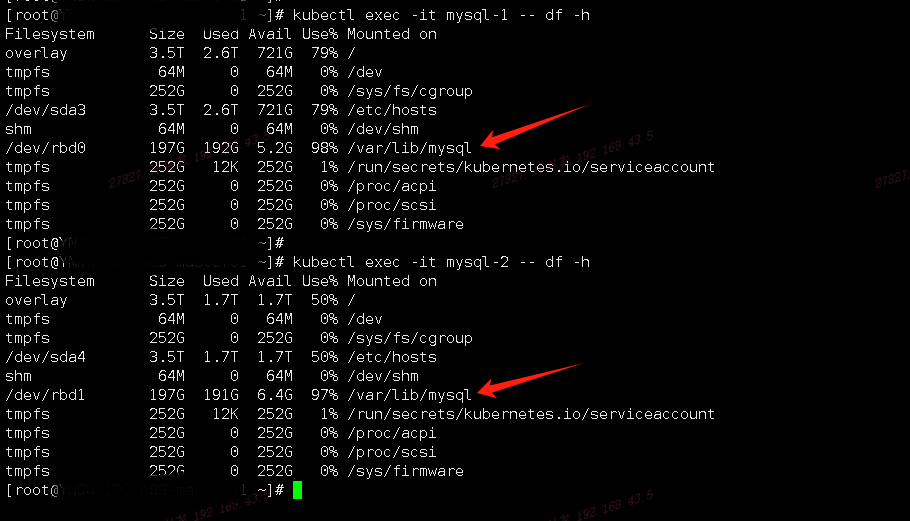
从库MySQL磁盘挂载(rbd0)IO情况,看到rbd0磁盘%util超过90%一直处在繁忙状态
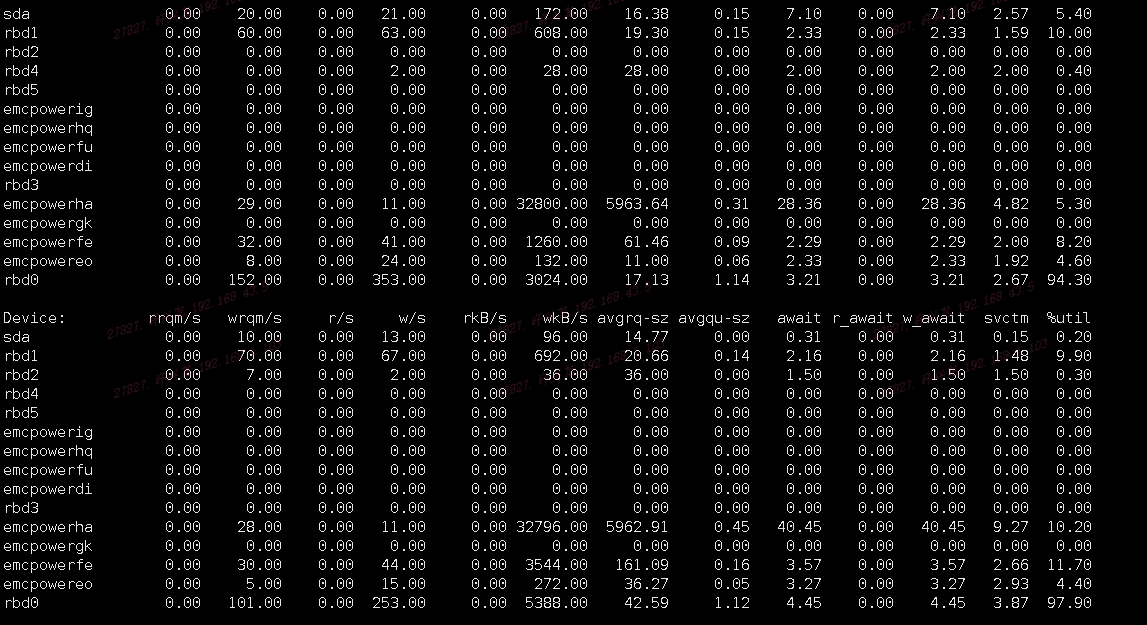
查看防火墙规则,没什么限制
通过主库建立测试库操作来验证主从同步延迟情况,在test测试库下删除t2表
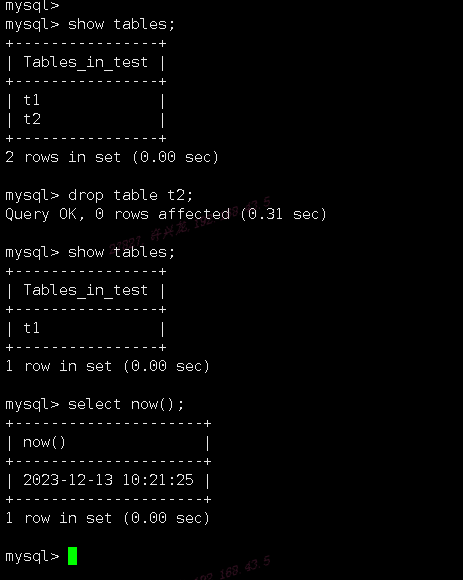
从库查看test库下表情况,半小时过去后从库t2表依然未删除,从库事务执行差距很大,查询过事务队列在堆积
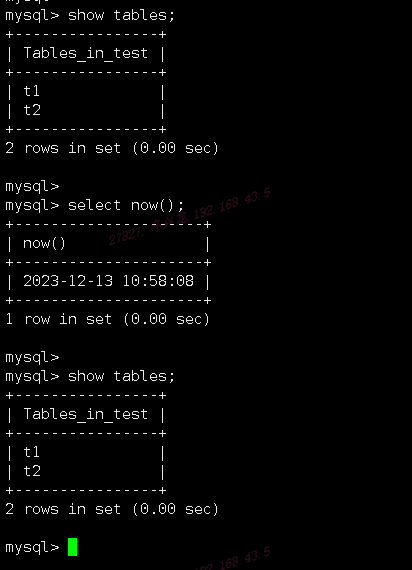

中继日志积压一大堆未完成,导致从库磁盘使用率超过90%爆满
分析
经过一番排查,可以看到的是:
1. MySQL数据库所存储磁盘IO比较繁忙
2. 从库中继日志堆积太多
3. 从库事务日志一直堆积,并且事务延迟越来越大
针对上面这些排查开始分析问题原因。是否跟硬件有关?是否达到磁盘性能上限?网络带宽是否充足?主、从库硬件环境一致,主库都能完成各种SQL操作,从库查看当前进程都没有几个,主要是同步主库SQL并回放执行,硬件限制暂时排查。
从库可以同步主库数据,就是同步数据延迟较大,说明同步复制状态还是正常的。那问题就集中在从库中继日志的回放上,MySQL MGR模式的复制同步跟传统复制模式原理上也是相似的,再回顾下同步复制原理,可以看到从库有两个主要进程IO thread、SQL thread,IO thread负载同步主库binlog日志,这一步从库数据同步还是正常的,这么看问题范围就集中在SQL thread这一步——读取IO thread从主库那里同步过来的数据进行SQL回放。有可能业务数据操作太多从库SQL thread无法及时处理。

处理
经过网上搜索一番MySQL主从复制延迟问题,发现官方从MySQL 5.7版本后支持并发复制功能enhanced multi-threaded slave(简称MTS)
开启MTS参数配置
gtid_mode = ON
enforce_gtid_consistency = ON
log_slave_updates = ON
log_bin = binlog
binlog_format = ROW
slave_preserve_commit_order=on # 参数在多线程复制环境下,能够保证从库回放relay log事务的顺序与这些事务在relay log中的顺序完全一致,也就是与主库提交的顺序完全一致,不设置该参数,start group_replication时会有报错启动失败
slave-parallel-type=LOGICAL_CLOCK # 关键参数, 支持事务级别的sql进行并发回放, 默认是database级别(也就是只能并发database)
slave-parallel-workers=16 # 并发回访的线程数, cpu数的一半
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
配置完这些参数后开启复制验证效果,发现从库延迟问题解决了,主库的相关操作能及时同步到从库。观察几天从库中继日志也可以很快回放掉不会出现大量堆积
- 重点关注的是Secondary节点的事务状态,更确切的说是关注待认证事务及待应用事务队列大小。
执行下面的SQL即可查看,主要关注非Primary节点的 COUNT_TRANSACTIONS_IN_QUEUE 和 COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE值大小
SELECT MEMBER_ID AS id, COUNT_TRANSACTIONS_IN_QUEUE AS trx_tobe_verified, COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE AS trx_tobe_applied, COUNT_TRANSACTIONS_CHECKED AS trx_chkd, COUNT_TRANSACTIONS_REMOTE_APPLIED AS trx_done, COUNT_TRANSACTIONS_LOCAL_PROPOSED AS proposed FROM performance_schema.replication_group_member_stats;
![]()
其中,COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE 的值表示等待被apply的事务队列大小,COUNT_TRANSACTIONS_IN_QUEUE 表示等待被认证的事务队列大小,这二者任何一个值大于0,都表示当前有一定程度的延迟。
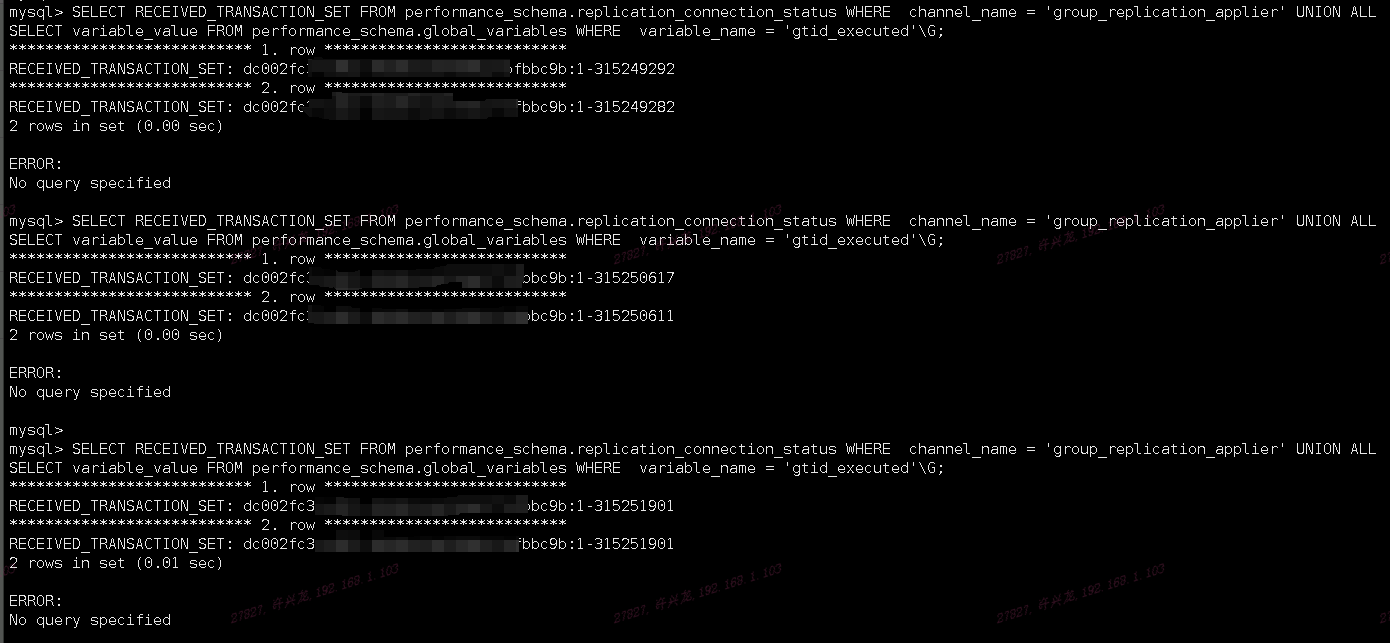
- 查看接收到的事务和已执行完的事务之间的差距
SELECT RECEIVED_TRANSACTION_SET FROM performance_schema.replication_connection_status WHERE channel_name = 'group_replication_applier' UNION ALL SELECT variable_value FROM performance_schema.global_variables WHERE variable_name = 'gtid_executed'\G;
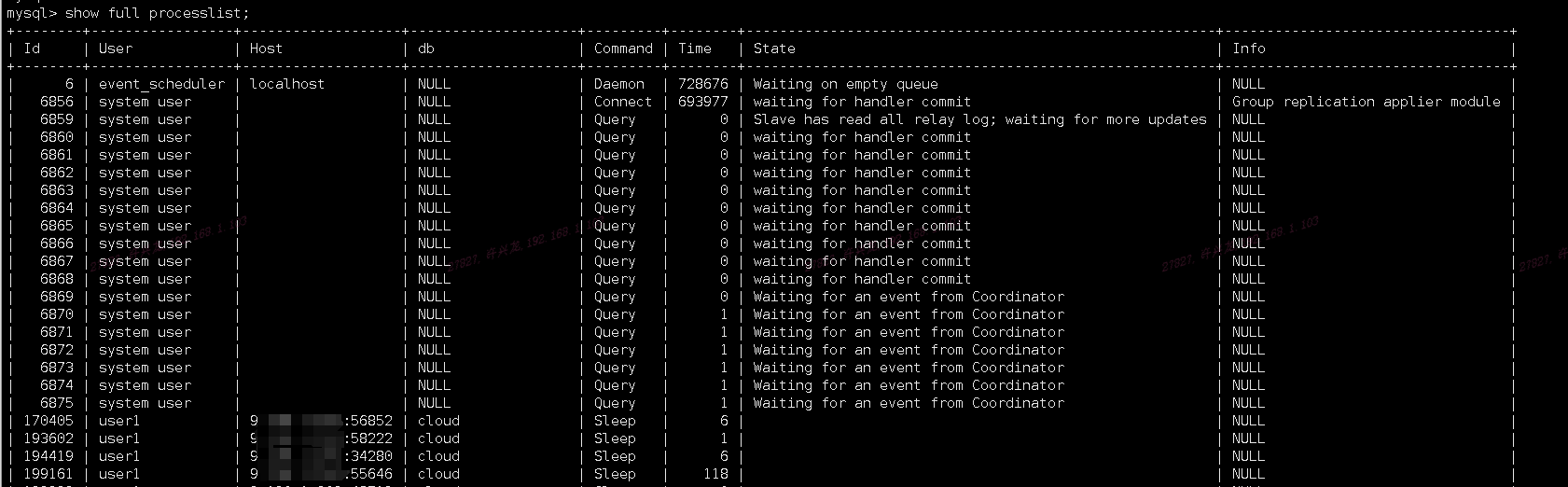
- 进程状态
参考文档
https://www.cnblogs.com/greatsql/p/17052055.html
https://www.cnblogs.com/caibaotimes/p/14667438.html





